聰明不如鈍筆
총명불여둔필

세상을 살다 보면 .csv 파일을 합쳐야 할 때가 생깁니다.
CSV(Comma-Separated Values) 파일은 기본적으로 그냥 텍스트 형식입니다.
그래서 (좀 많이 귀찮기는 하지만) 사실 메모장에서 Ctrl+C/V만 해도 파일을 합칠 수 있습니다.
자동으로 병합 과정을 진행할 때도 (마이크로소프트·MS 윈도 기준으로) 메모장만 있으면 됩니다.
첫 단계는 합치고 싶은 CSV 파일을 폴더 한곳에 모으는 것.
그다음 메모장을 열고 아래 형식으로 MS-DOS 명령어를 입력해 둡니다.
copy *.csv [새 파일 이름].csv
예를 들어 파일을 합쳐서 'test_all.csv'이라는 파일을 만들고 싶다면 이렇게 입력하면 됩니다.

여기서 '*'은 와일드카드 문자 가운데 '모든'을 뜻하는 녀석입니다.
그러니까 이 명령어는 모든 .csv로 끝나는 모든 파일을 test_all.csv에 복사하라는 뜻이 됩니다.
Ctrl+C/V를 반복해 주는 명령어인 셈입니다.
이렇게 만든 텍스트 파일을 CSV 파일을 모아 놓은 폴더에 저장합니다.
이때 파일 이름은 반드시 '.bat'라는 표현으로 끝나야 합니다.
예를 들어 저는 이 파일을 'merge_CSVs.bat'라고 저장했습니다.
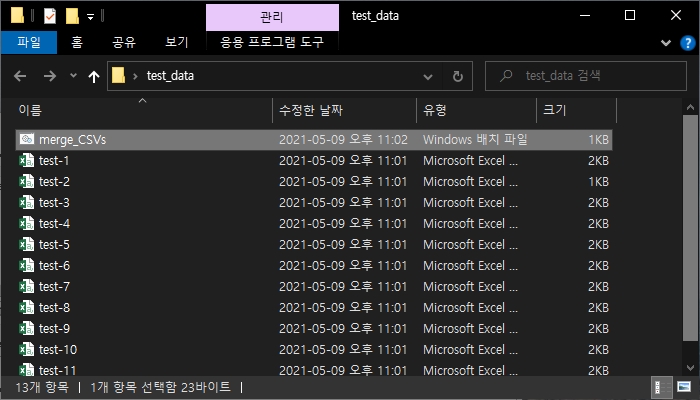
'.bat'은 DOS에서 '배치(batch) 파일'을 만들 때 쓰는 확장자입니다.
원래 윈도에서 도스 명령어를 실행할 때는 '명령 프롬프트'를 실행해야 합니다.
배치 파일을 만들어 이 파일을 실행하면 자동으로 명령 프롬프트에서 이 명령어를 실행하게 됩니다.
그러니까 다음 단계는 이 .bat 파일을 실행(더블 클릭)하는 겁니다.
그러면 파일을 만들 때 정한 이름으로 새 CSV 파일을 만든 걸 확인할 수 있습니다.

test_all.csv 파일을 열어 보면 '첫 행'에 해당하는 열 이름이 겹쳐 나온다는 사실을 알 수 있습니다.
이건 그냥 데이터 정렬 같은 방법으로 한 데 모아서 지우면 됩니다.
예제 데이터에서는 date 열을 기준으로 정렬을 한 다음 맨 아래 있는 열을 선택해 지우면 됩니다.
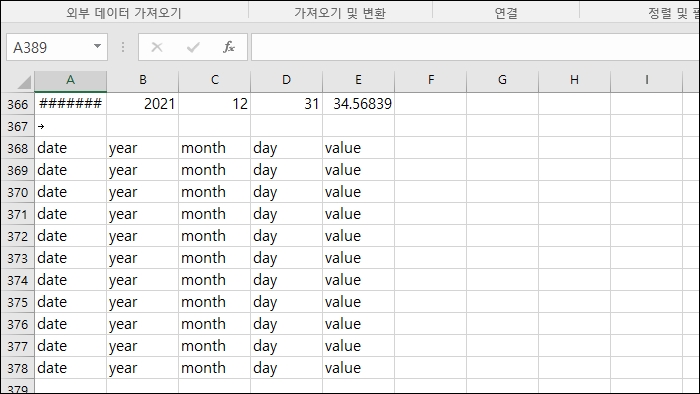
아, 예제 데이터는 1월 1일부터 12월 31일까지 그냥 아무 의미 없는 숫자를 value 열에 담은 형식입니다.
월 별로 나눠 놓은 예제 파일은 아래 링크를 통해 내려받으실 수 있습니다.
물론 R나 파이선 같은 프로그래밍 언어를 통해서 CSV 파일을 합치는 방법도 있습니다.
예제 데이터는 파일 이름이 'test-1.csv', 'test-2.csv', 'test-3.csv' … 'test-12.csv' 형태입니다.
따라서 R에서는 아래 같은 코드를 쓰면 이 파일 12개를 한번에 불러올 수 있습니다.
library('tidyverse')
library('glue')
map(1:12, ~read.csv(glue('test-{.x}.csv'))) %>%
bind_rows() %>%
as_tibble()## # A tibble: 365 x 5 ## date year month day value ## <chr> <int> <int> <int> <dbl> ## 1 2021-01-01 2021 1 1 73.8 ## 2 2021-01-02 2021 1 2 31.5 ## 3 2021-01-03 2021 1 3 66.1 ## 4 2021-01-04 2021 1 4 88.7 ## 5 2021-01-05 2021 1 5 4.87 ## 6 2021-01-06 2021 1 6 73.4 ## 7 2021-01-07 2021 1 7 90.7 ## 8 2021-01-08 2021 1 8 10.1 ## 9 2021-01-09 2021 1 9 44.2 ## 10 2021-01-10 2021 1 10 42.7 ## # ... with 355 more rows
R는 열 이름을 기준으로 데이터를 합치기 때문에 따로 열 이름을 지울 필요가 없습니다.
파이선에서는 이렇게 쓰면 됩니다.
폴더 안에 있는 test*.csv 파일을 전부 불러와서 읽는 방식입니다.
'ignore_index = True' 옵션으로 열 이름이 들어 있는 행을 가져오지 말라고 지정했습니다.
import pandas as pd
import glob
import os
files = os.path.join("test*.csv")
files_list = glob.glob(files)
df = pd.concat(map(pd.read_csv, files_list), ignore_index = True)
print(df)date year month day value 0 2021-01-01 2021 1 1 73.849932 1 2021-01-02 2021 1 2 31.494913 2 2021-01-03 2021 1 3 66.144703 3 2021-01-04 2021 1 4 88.716588 4 2021-01-05 2021 1 5 4.874716 .. ... ... ... ... ... 360 2021-09-26 2021 9 26 35.156030 361 2021-09-27 2021 9 27 74.441386 362 2021-09-28 2021 9 28 5.142641 363 2021-09-29 2021 9 29 0.319863 364 2021-09-30 2021 9 30 14.532934 [365 rows x 5 columns]
cmd로 명령 프롬프터를 실행한 뒤 폴더 경로를 찾아가느라 고생하시는 분들께 또는 for 문을 써서 파일을 읽고 계신 분들께 이 포스트가 도움이 됐기를 바랍니다.
댓글,